[Kubernetes] k8s master 서버 HA 구성하기
안녕하세요? 정리하는 개발자 워니즈입니다. 이번시간에는 k8s master 서버의 가용성 환경 구성에 대해서 정리를 하고자 합니다. 필자는 kubespray를 통해서 cluster를 구축을 했는데요. 특별히 별도의 설정을 하지 않으며, master 1번 서버를 api-server로 사용하게 됩니다. 그러다보니 고가용성에서 문제가 발생을 하게 되어, LB를 연결하여 LB의 VIP를 바라보도록 설정하는 내용입니다.
1. 쿠버네티스 아키텍처
쿠버네티스는 control plane(master), storage system(etcd), 다수의 nodes(worker, kubelets)로 이루어져 있습니다.
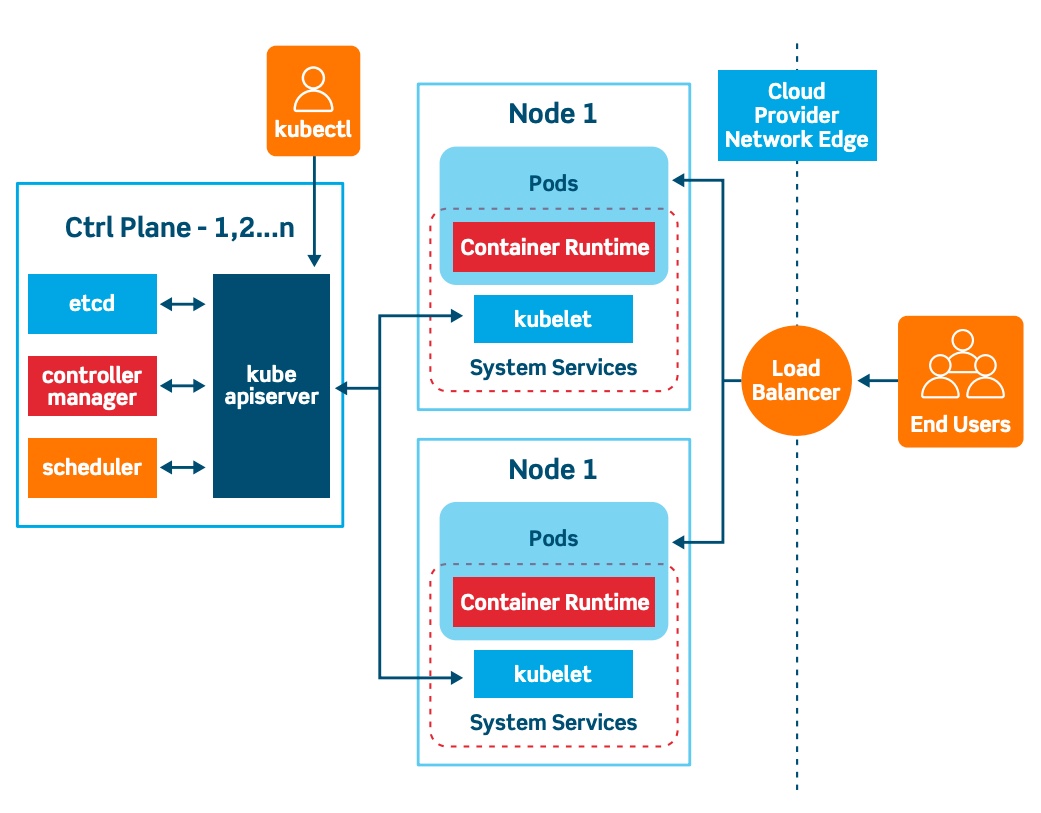
여기 부분에서 control plane(master)에 좀더 집중을 해서 확인을 해보겠습니다.
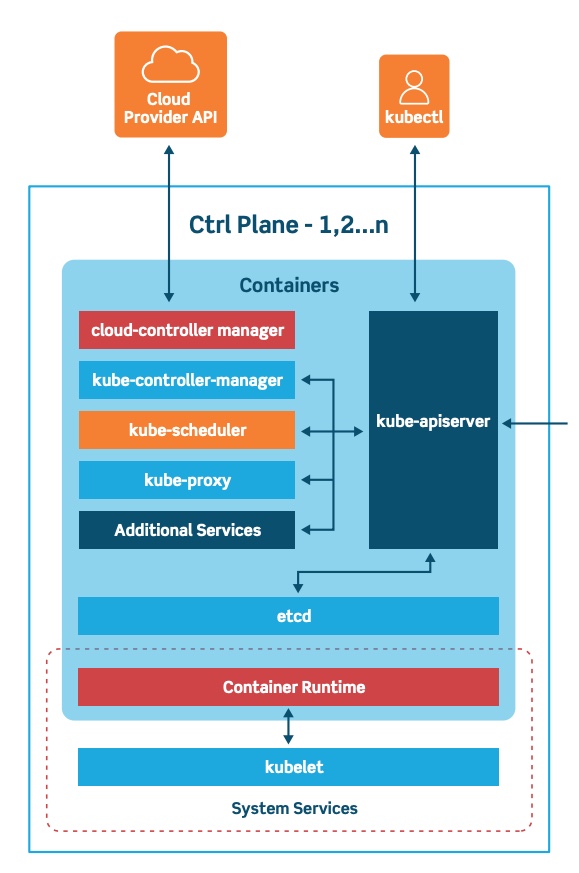
master 영역은 k8s의 개체를 기록하고 유지 관리하는 시스템입니다. 클러스터의 변경 사항에 응답하여 객체 상태를 지속적으로 관리합니다.
master 영역은 다음 세가지로 구성이 되어있습니다.
- kube-apister
API 서버는 다양한 유형의 어플리케이션에 대한 수명 주기 오케스트레이션(확장, 업데이트 등)을 지원하는 API를 제공합니다. 클라이언트는 API 서버를 통해 인증하고 이를 노드 및 포트에 대한 프록시 / 터미널로 사용합니다.
- kube-controller-manager
Controller Manager는 핵심 제어 루프를 실행하고 클러스터의 상태를 감시하며 원하는 상태로 드라이브 상태를 변경하는 데몬입니다.
- Kube-scheduler
Scheduler는 클러스터의 노드 전체에 걸쳐 컨테이너의 스케쥴링을 담당합니다. 리소스 제한 또는 보장, 선호도 및 반선호도 사양과 같은 다양한 조건을 고려합니다.
2. 현상태의 문제점
필자가 운영하는 서비스에서는 kubespray를 통해서 k8s를 설치했습니다. 그런데 위의 아키텍처에서 kube-apiserver가 master의 대수만큼 존재를 하게 되는데 여기서 1번서버하고만 통신을 하도록 초기 구성이 되어있었습니다.
즉, 과한 통신량을 받게 되면 Master는 혼자서 감당하기 힘들며 1번 서버에 문제가 생겨 고장나면 api-server가 통신을 못하게 되므로 k8s cluster에 영향을 받게 됩니다. 따라서 이를 고가용성으로 Load Balancing에 api-server를 연결하여 LB와 통신을 하도록 변경하고자 합니다.

위의 구성과 같이 LB를 통해서 모든 worker nodes와 client들이 통신을 수행하도록 구성을 하고 etcd는 각 master 서버에 구성되는 stacked etcd cluster를 구성할 예정입니다.
2. LB 신규 생성
필자가 속한 회사에서는 사내의 Private Cloud가 존재하고 그곳에서 손쉽게 LB를 생성할 수 있습니다.
LB의 6443 포트로 접속을 하면 3대의 master 서버로 분산을 해주도록 설정을 했습니다.

3. k8s upgrade
이제 준비는 모두 됐고, k8s의 모든 설정들을 LB의 endpoint를 보도록 변경을 하고 해당 내용을 반영해주는 작업을 수행합니다.
How to convert a Kubernetes non-HA control plane into an HA control plane?
위의 내용을 정리해오면서 알게 된것은 초기 k8s cluster 구축시기부터 HA로 구성을 해야한다는 것입니다. 필자는 Non-HA구성을 HA구성으로 전환하려는 것인데, 이는 추천하는 방식이 아니라고 합니다.
3-1. Upgrade the kube-apiserver certificate
kube-apiserver는 control plane 트래픽을 암호화 하는 인증서를 갖고, 이 인증서는 SAN(Subject Alternative Name) 이라고 알려진 객체를 갖고 있습니다. SAN은 API에 접근하는데 사용되는 IP리스트를 갖고 있습니다.
그래서 초기 작업은 이 SAN의 IP리스트를 LB의 endpoint로 업데이트 하는 것입니다.
...
controlPlaneEndpoint: 10.128.174.74:6443
certificatesDir: /etc/kubernetes/ssl
imageRepository: k8s.gcr.io
...
certSANs:
- 10.128.174.74
...
kube-apiserver를 업데이트하기 전에 /etc/kubernetes/pki의 apiserver 관련된 cert 파일을 지우거나 백업을 해둡니다.
$ mkdir /etc/kubernetes/pki_bak
$ cd /etc/kubernetes
$ mv /etc/kubernetes/pki/apiserver.crt /etc/kubernetes/pki_bak
$ mv /etc/kubernetes/pkiapiserver.key /etc/kubernetes/pki_bak
#kubeadm을통한 인증서 갱신
$ kubeadm init phase certs apiserver --config kubeadm-config.yaml
3-2. Update the kubelet, the scheduler and the controller manager kubeconfig files
다음스텝은 kube-apiserver와 통신하는 kubelet, scheduler 그리고 controller-manager를 모두 LB의 endpoint로 업데이트를 해주는 것입니다.
- /etc/kubernetes/kubelet.conf
- /etc/kubernetes/scheduler.conf
- /etc/kubernetes/controller-manager.conf
위의 파일에서 server: 영역을 kube-apiserver에서 LB의 endpoint로 변경을 수행합니다.
# kubelet restart
systemctl restart kubelet
# scheduler, controller-manager restart
kill -s SIGHUP $(pidof kube-controller-manager)
kill -s SIGHUP $(pidof kube-scheduler)
3-3. Update the kube-proxy kubeconfig files
다음스텝은 kube-proxy의 server:영역을 LB의 endpoint로 업데이트를 수행합니다.
$ kubectl edit cm kube-proxy -n kube-system
변경하고나서 업데이트를 하는것을 잊지 말라고 되어있지만, 실제로 kube-proxy같은 경우 필자는 자동으로 업데이트가 되어있어 이부분은 스킵하고 지나갔습니다.
3-4. Update the kubeadm-config configmap
마지막 스텝으로는 모든 준비가 됐으므로, kubeadm을 통해서 클러스터에 대한 업그레이드를 진행합니다. 최초에 kubeadm-config를 수정했으므로 이를 반영해준다고 보면 됩니다.
$ kubeadm upgrade apply --config kubeadm-config.yaml --ignore-preflight-errors all --force --v=5
3-5. Update the cluster-info configmap
추가적인 내용인데, cluster 정보를 표기할 때, 이부분이 새로 작성한 LB의 endpoint로 노출이 되도록 설정을 업데이트 하는 내용입니다. master의 1대에서 작업을 하면 되고 아래의 커맨드를 통해서 업데이트 합니다.
$ kubectl -n kube-public edit cm cluster-info
3-5. 다른 마스터 노드 업그레이드
업그레이드는 클러스터의 모든 마스터를 업데이트하지 않고 현재 있는 마스터만 업그레이드를 진행합니다. 따라서 다른 2대의 마스터노드에서도 위의 작업을 동일하게 수행해줍니다.
4. 테스트
이번 HA 구성의 목적은 개별적인 master node의 api-server 프로세스가 내려가더라도 다른 노드를 통해서 k8s의 api 호출이 가능하도록 구성을 하는 것 입니다. 그렇기 때문에 테스트는 master node를 임의로 서비스를 내려두고 호출을 했을 경우, 정상적으로 되는지를 확인 해 봅니다.
4-1. 각 master 서버에서 실행
각 master 서버의 api-server를 한번 내려보고 재기동 되는 사이 바로 api 호출을 통해서 정상적으로 호출이 되는지를 확인 해봅니다.
# master 1번 서버
$ kill -s SIGHUP $(pidof kube-apiserver)
# master 1번 서버
$ kubectl get pod
No resources found in default namespace.
4-2. 각 master를 제외한 나머지 2대 서비스 중지
# master 2,3번 서버
$ kill -s SIGHUP $(pidof kube-apiserver)
# master 1번 서버
$ kubectl get pod
No resources found in default namespace.
이전에는 4-1케이스 같은 경우, 정상적으로 호출이 되지 않았을 것입니다. 이제는 각 master 서버의 api-server를 바라보는 것이 아니라, LB의 end-point를 바라보고 있기 때문에 다른 하나가 문제가 발생을 하더라도 정상적으로 호출이 가능할 것 입니다.
5. 마치며..
이번시간에는 master 서버의 HA 구성에 대해서 정리를 해보았습니다. 서두에도 정리했듯이 non-HA구성에서 HA구성으로 가는 것은 지양하고 있습니다. 최초에 클러스터 구축시 HA를 고려하여 kubespray의 코드를 변경하는 것이 더 좋아 보입니다.
다음시간에는 kbuespray를 통한 node 증설에 대해서 정리를 해보도록 하겠습니다.
6. 참조
kubeadm Master 3개 설정 (Haproxy)
How to convert a Kubernetes non-HA control plane into an HA control plane?
kubeadm – How to “upgrade” (update) your configuration
Creating Highly Available Clusters with kubeadm