[Kubernetes] Pod Configuration & Resource Limit
안녕하세요? 정리하는 개발자 워니즈 입니다. 이번시간에는 쿠버네티스 파드 설정 에 대해서 알아보도록 하겠습니다. 먼저 지난 시간에는 Pod, Service, Deployment 라는 개념에 대해서 알아봤는데요. 쉽게 이야기해서 Pod는 서비스 할 수 있는 컨테이너를 담아주는 내용이고, 서비스는 그러한 Pod들을 연결시켜주는 네트워크에 대한 내용이었고, Deployment는 Pod해 대한 내용을 배포해주는 내용입니다.
이번시간에는 Pod들의 내부 설정에 따라, 배포시 어떠한 동작을 하는지 알아보도록 하겠습니다.
지난 글들은 아래를 참고 해주시면 됩니다.
- 쿠버네티스 1편 : 설치 가이드
- 쿠버네티스 2편 : pod
- 쿠버네티스 3편 : service
- 쿠버네티스 4편 : deployment
- 쿠버네티스 5편 : pod 설정
- 쿠버네티스 6편 : 배포 전략
- 쿠버네티스 7편 : volume
- 쿠버네티스 8편 : daemonset
- 쿠버네티스 9편 : 테라폼을 통한 클러스터 구성
- 쿠버네티스 10편 : eks에서 volume 사용하기
- 쿠버네티스 11편 : helm
- 쿠버네티스 12편 : helm chart template
- 쿠버네티스 13편 : helm deploy
- 쿠버네티스 14편 : fluentd를 통한 log수집
- 쿠버네티스 15편 : chartmuseum
- 쿠버네티스 16편 : 배포툴(ArgoCD 설치방법/사용법)
- 쿠버네티스 17편 : 배포툴(ArgoCD 구성/알람)
- 쿠버네티스 18편 : 쿠버네티스 Autoscailing
- 쿠버네티스 19편 : 쿠버네티스 로깅 아키텍처

위의 그림에서 보시는것처럼, 무중단으로 배포되고 운영되는 시나리오라면, Pod의 문제가 생기게 되면, 그 Pod를 새로이 생성하고 서비스를 해야되는 상황이 발생할 것입니다.
이 경우 몇가지 문제점에 맞딱드리게 됩니다 .
- 새로운 Pod 생성시 쿠버네티스는 어느시점에 트래픽을 보낼까? 보통의 어플리케이션이라면 서비스가 올라오는 데까지 수초내지는 수분이 걸립니다. 서비스가 아직 기동중이지 않은 상황에서 트래픽을 보내게 되면, 정상적인 응답을 할 수 없을 것입니다.
- 다른상황으로, Pod에 문제가 생긴다면, 쿠버네티스 입장에서 해당 Pod를 내리고, 새로운 Pod를 생성해야됩니다. 그러나 실질적으로는 Pod내부의 어플리케이션의 정상 여부를 체크해야됩니다. 만약, 해당 부분을 체크하지 못한다면 요청을 지속적으로 보낼 것입니다.
정리를 하자면, 다음과 같습니다 .
- Pod내부의 어플리케이션 정상 서비스 여부를 알 수 있나요?
결국 두가지 모두 내부의 서비스에 대한 이상 여부를 체크해야 합니다.
1. Container probes
아래의 내용은 Google Cloud의 Kubernetes best practice article을 기반으로 작성되었습니다.
쿠버네티스의 가장큰 장점은 스스로 어플리케이션에 대한 동작을 체크해주고, 지속적인 헬스체크로 고품질의 서비스 상태를 유지한다는 것입니다.
Health check는 어플리케이션에 문제가 있는지 확인 할 수 있는 가장 간단한 방법입니다. 만약 정상적으로 동작하지 않는다면, 요청을 보내서는 안되고, 정상적인 상태로 기존의 Pod를 내리고 새로운 Pod를 올려야합니다. 물론, 신규 Pod에 대해서도 서비스가 정상적으로 올라왔느지에 대한 체크를 수행합니다.
1. 헬스체크의 종류
Kubernetes 에서는 두가지 헬스 체크 기능을 제공합니다.
1. Readiness
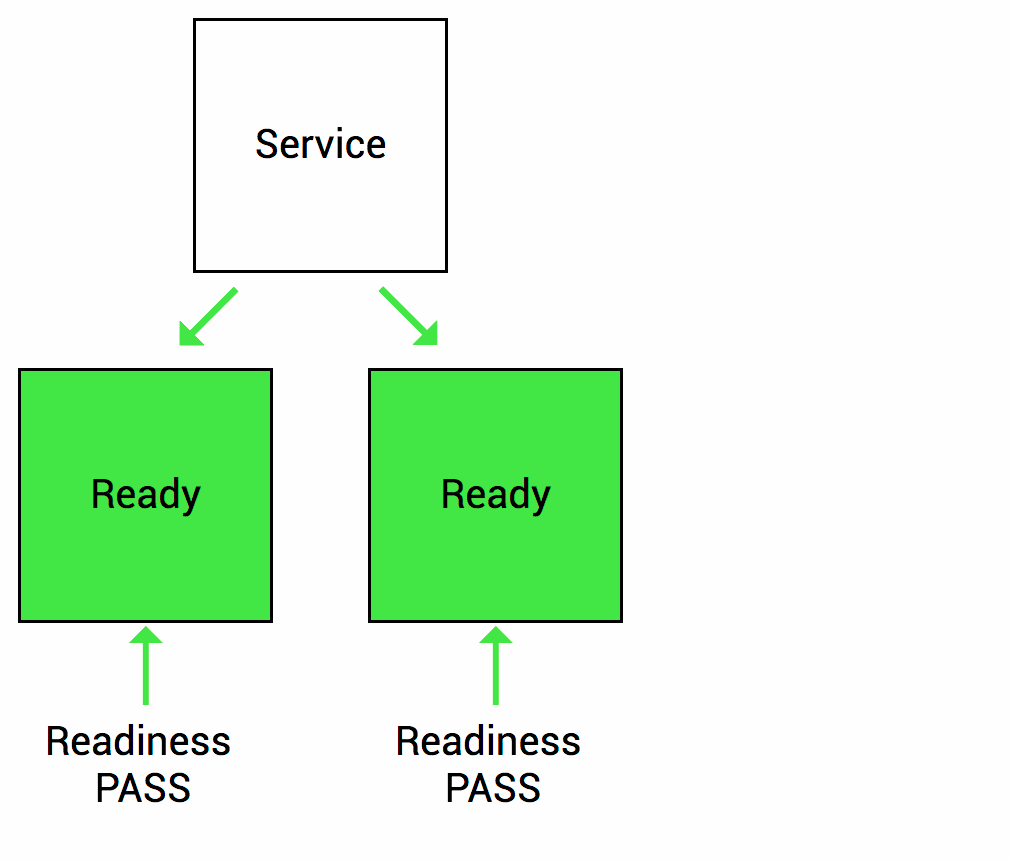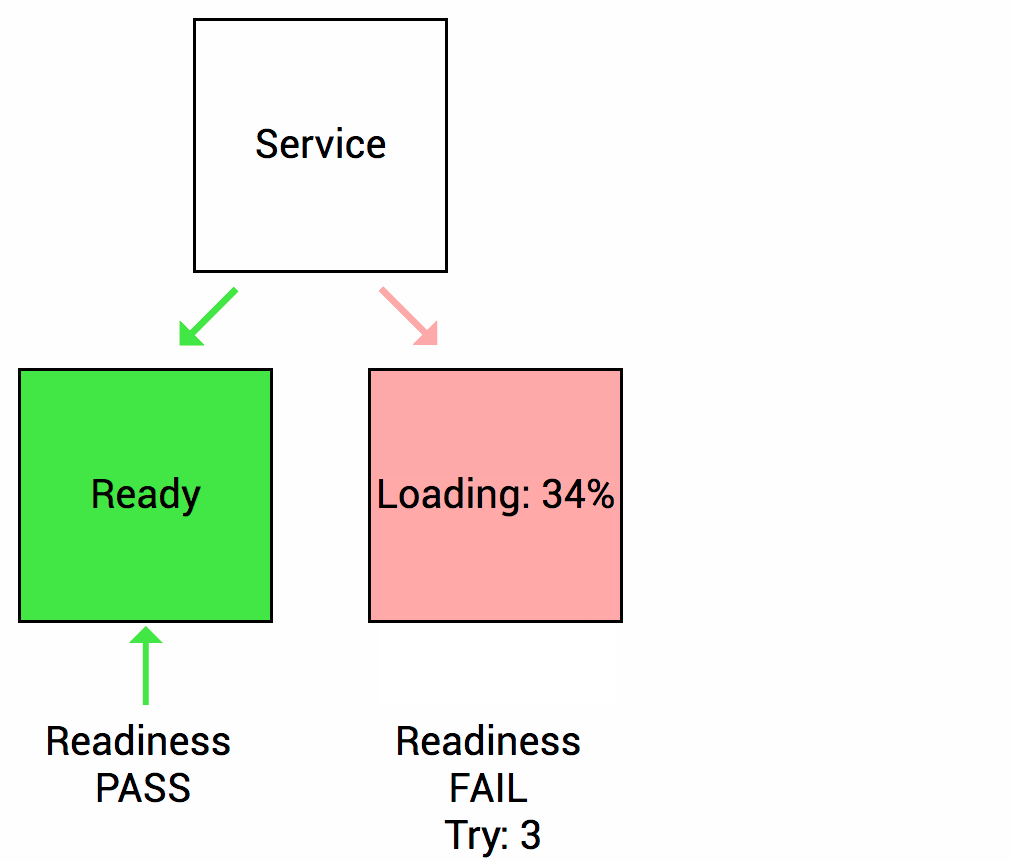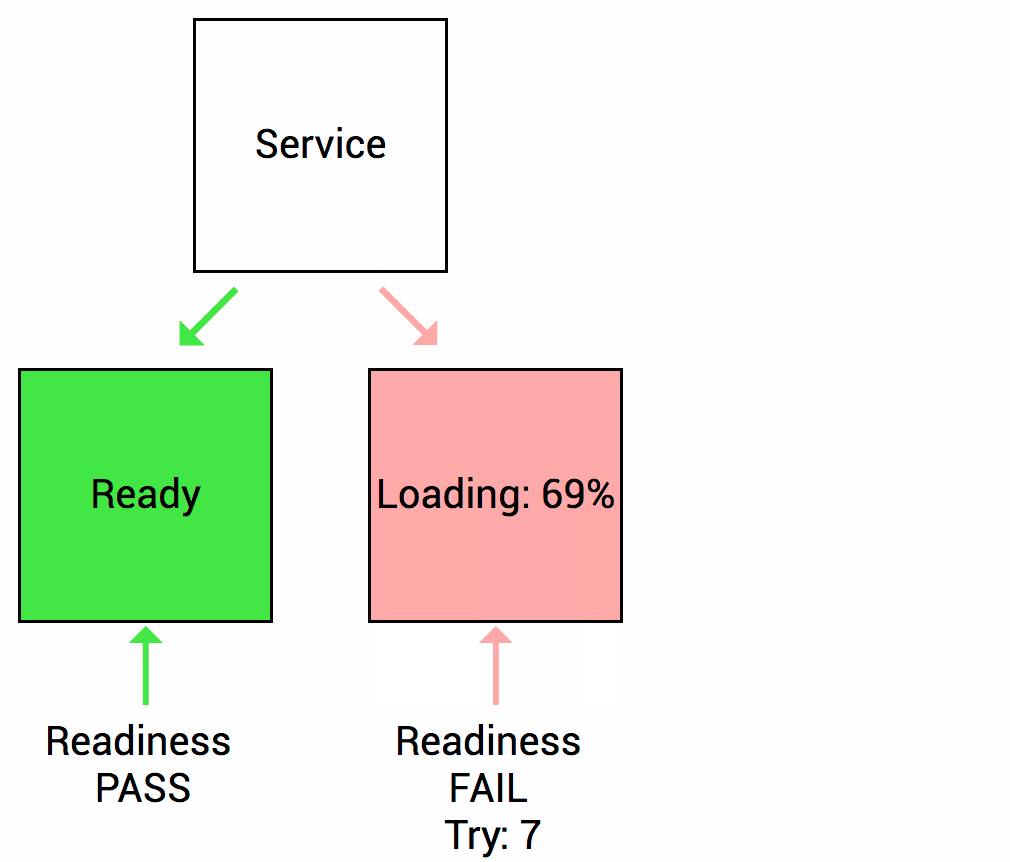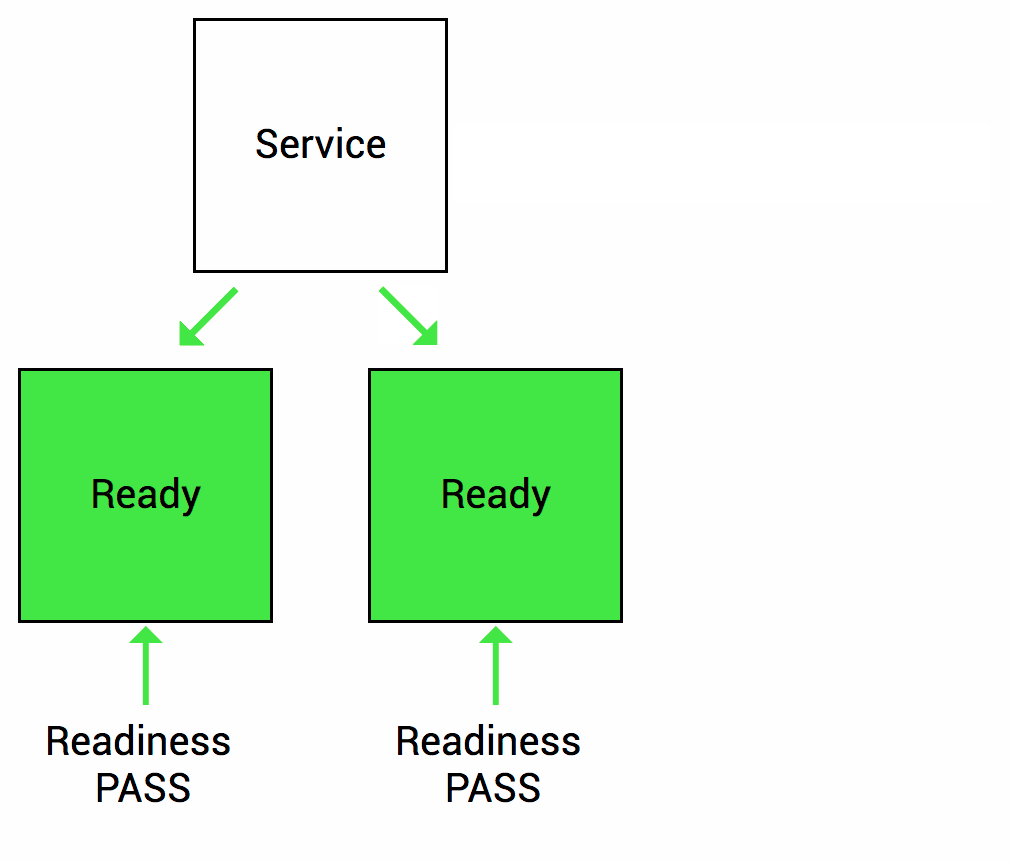
Readniness probe는 Container안의 어플리케이션이 서비스 할 준비가 되면 쿠버네티스에게 알리도록 설계 되어있습니다. 서비스가 Pod로 트래픽을 보내기전에 Readiness probe 검사단계가 통과되어아먄 해당 Pod로 트래픽을 보내는 것을 의미합니다.
예를 들어, 애플리케이션이 시작되고 서비스되기까지 얼마정도의 시간이 걸린다고 가정해봅시다. 이러한 상황에서는 Container의 프로세스가 시작되더라도 애플리케이션이 서비스를 받아들일 준비가 되지 않았으므로, Kubernetes의 Service가 트래픽을 보내더라도, 실제 애플리케이션은 동작하지 않게되지만, Kubernetes는 기본적으로 Container 프로세스가 시작되면 트래픽을 보내기 때문에 문제가 발생 할 수 있습니다. 이러한 경우에 우리는 readiness probe를 사용해 문제를 해결할 수 있게 되는 것입니다. readiness probe 검사단계를 적용하면 Kubernetes는 readiness probe가 통과되어야만 트래픽을 Pod로 보내게되므로 문제가 발생하는 상황을 미연에 방지할 수 있습니다.
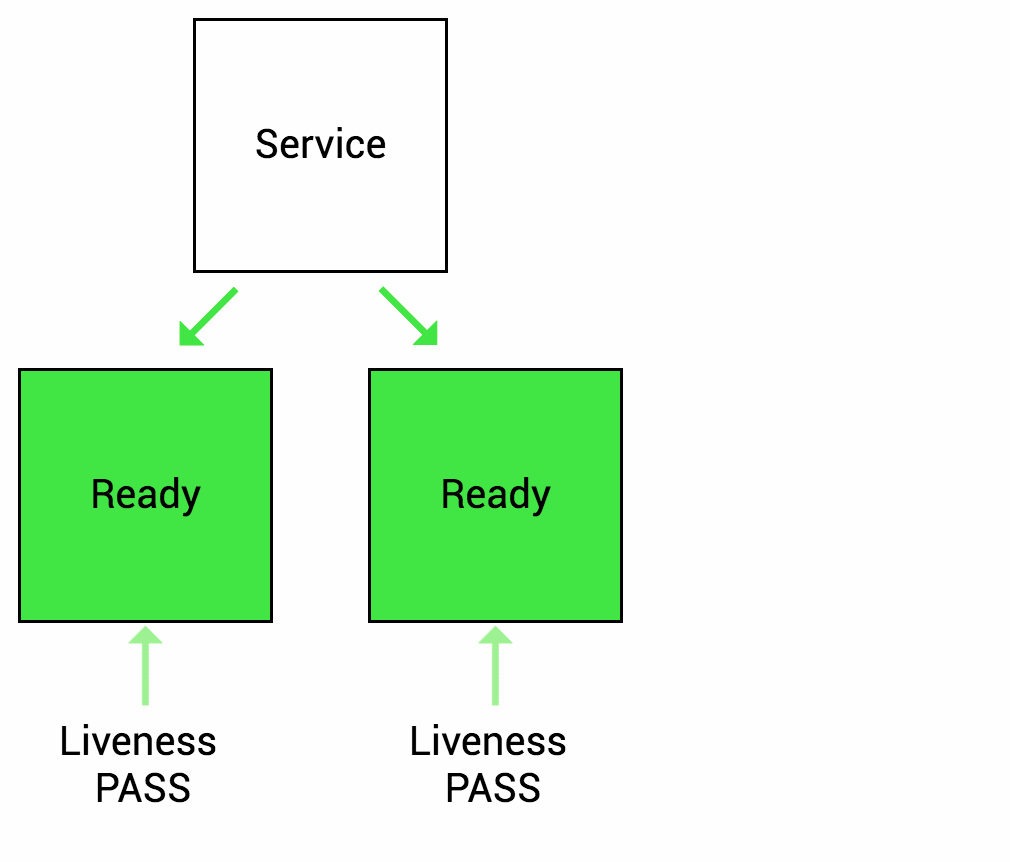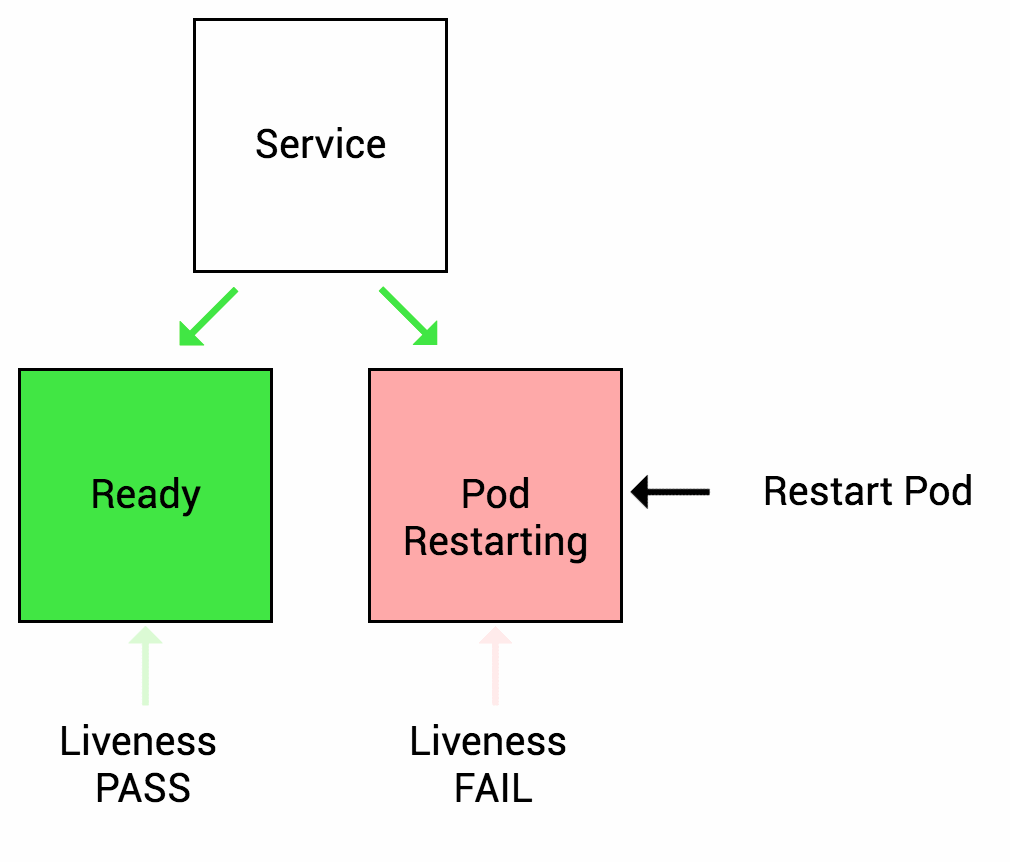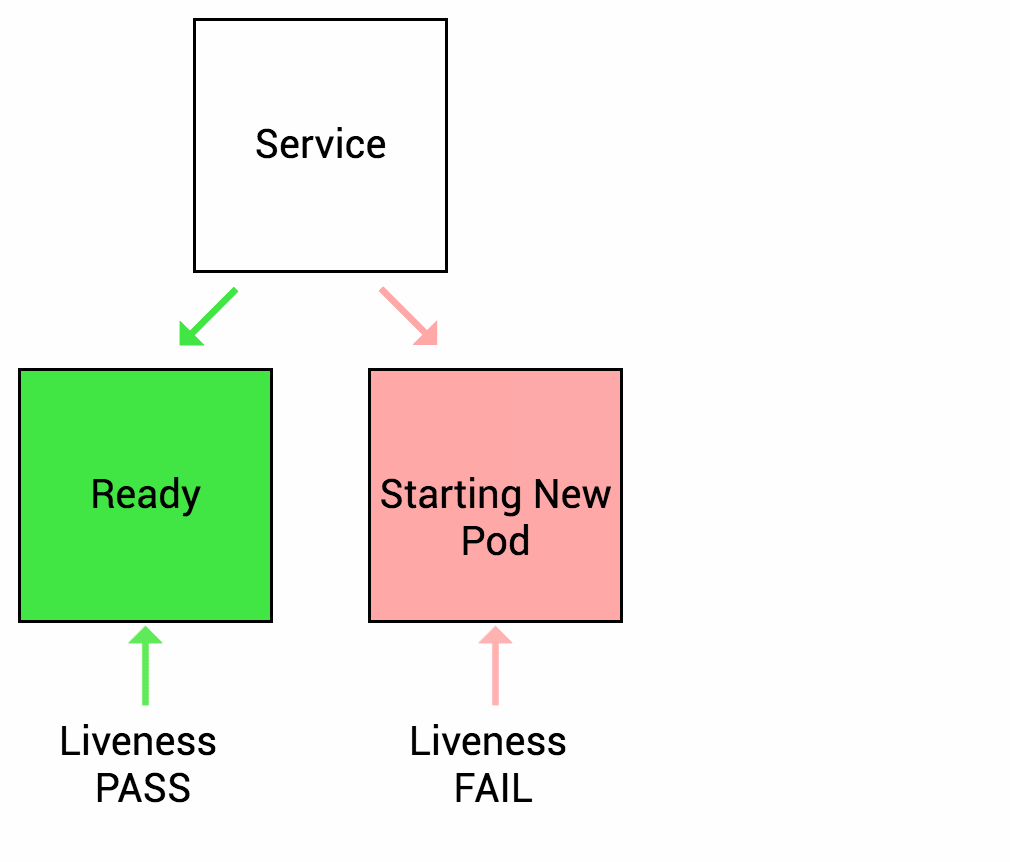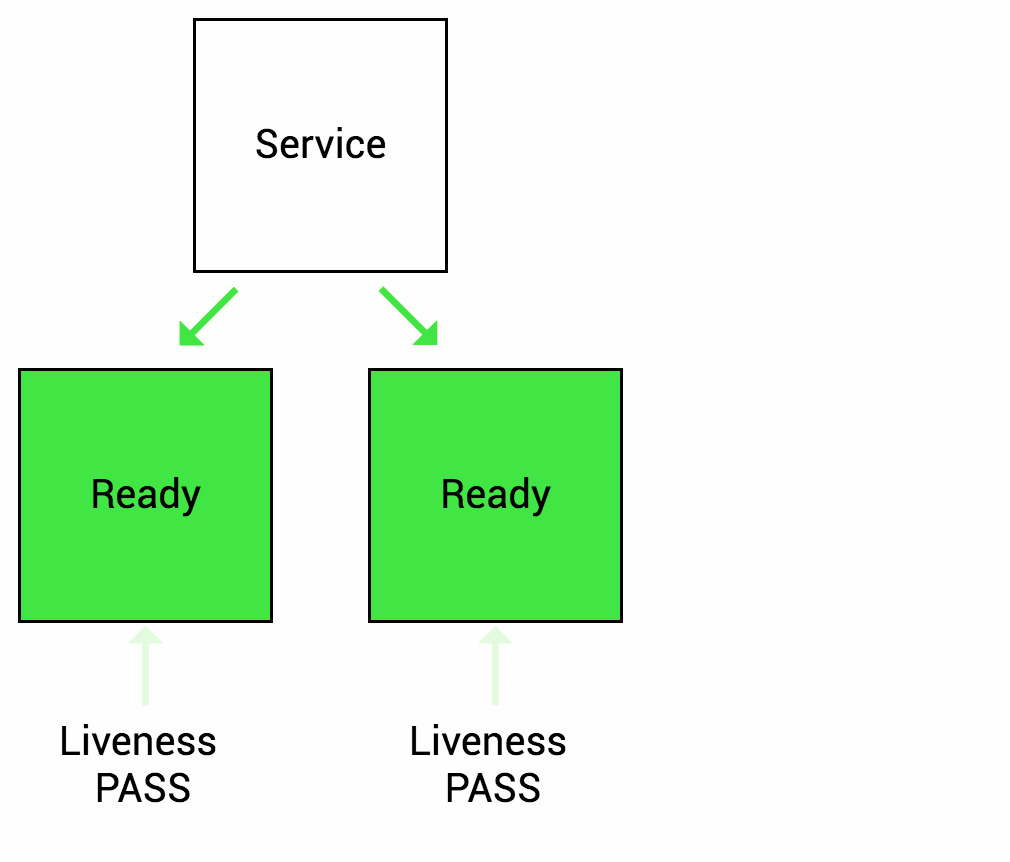
2. Liveness
Liveness probe는 배포된 어플리케이션의 상태가 정상인지 비정상인지 여부를 판단하여 Kubernetes에 알리도록 설계되어 있습니다. 만약 어플리케이션에 문제가 발생하면 Kubernetes는 문제가 발생한 Pod를 제거하고 새로운 Pod를 시작하게 됩니다.
예를 들어, 배포한 애플리케이션에 Deadlock이 발생하여 더이상 서비스를 제공할 수 없는 상태가 되었다고 가정해봅시다. 이러한 경우에도 Container의 프로세스는 동작중이기 때문에 기본적으로 Kubernetes 문제가 발생한 Container의 상황을 인지할 수 없게 되고 문제가 발생한 애플리케이션으로 트래픽을 계속 보내게 됩니다. Liveness probe를 적용하게 되면 Kubernetes에서 문제가 발생한 애플리케이션의 상황을 인지해 새로운 Container를 시작할 수 있기 때문에 이러한 상황을 미연에 방지할 수 있습니다.
2. 프로브의 종류
Probe는 Kublet에 의해 주기적으로 수행되는데, 아래의 3가지 타입으로 Container에 구현된 Handle를 호출함으로써 Health Check를 수행합니다.
1. HTTP
HTTP probe는 가장 일반적으로 사용되는 liveness probe 타입입니다. 어플리케이션의 HTTP 서버로 probe 에 설정한 트래픽을 보내 200 ~ 400 의 응답코드를 받으면 정상, 그 이외의 응답코드를 받으면 비정상으로 마킹합니다.
2. Command
command probe는 Container안에서 해당 command를 수행한 결과가 정상인지 여부를 체크하는 probe타입으로 만약 command 수행결과 코드가 0이 리턴되면 정상, 그렇지 않으면 비정상으로 마킹합니다. command probe 타입은 어플리케이션에 HTTP 서버를 실행할 수 없을 경우 유용하게 사용될 수 있습니다.
3. TCP
TPC probe 타입은 Kubernetes가 지정된 포트로 TCP 연결을 시도해 연결에 성공하면 정상, 연결할 수 없다면 비정상으로 마킹하게 됩니다. TCP Probe는 HTTP probe나 command probe를 사용 할 수 ㅇ벗을 경우에 유용하며, 대표적인 유형으로 gRPC 나 FTP service가 있습니다.
3. Liveness & Readiness 프로브의 설정
1. HTTP request liveness 에 대한 정의
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
위의 내용에 대해서 하나씩 살펴보도록 하겠습니다.
periodSeconds: 3
liveness probe의 수행주기를 설정하는 필드로 위 예제에서는 매 3초마다 liveness probe를 수행하게 됩니다.
initialDelaySeconds: 3
Pod가 생성되고 Container가 시작된 이후 최초 probe가 수행되기전에 Delay를 주는 시간
가장 중요한 것은 초기 지연 시간을 적절하게 설정함으로써, 어플리케이션이 구동되는 시간을 확보하는 것입니다. 만약 초기 지연시간이 너무 짧은 상태로 liveness probe가 동작하면 Pod가 정상 수행하지 않는 것으로 판단하고 Pod를 내리고 신규 Pod를 올리는 일을 반복 수행합니다.
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds이후에 kubelet은 HTTP GET request를 Container안에서 동작하고 있는 server의 8080 포트로 /healthz path에 요청을 보낼것입니다. 위에서 언급했듯이 success code를 리턴하게 되면, kubelet은 Container가 정상동작하고 있다고 마킹 할 것이고 만약 failure code를 리턴한다면 Container를 제거하고 다시작할 것입니다.
2. liveness command에 대한 정의
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
periodSecondsliveness probe의 수행주기를 설정하는 필드로 위 예제에서는 매 5초마다 liveness probe를 수해하게 됩니다.initialDelaySecondsPod가 생성되고 Conainer가 시작된 이후 최초 probe가 수행되기전에 Delay를 주는 시간
nitialDelaySeconds이후에 kubelet은 Container안에서 cat /tmp/healthy 명령을 수행 할 것입니다. 그 결과 리턴된 코드가 0이면 정상 그렇지 않으면 비정상을 마킹하게 되고, Container를 재시작하게 됩니다.
3. TCP liveness 프로브 정의
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
위의 예제는 readiness와 liveness probe를 모두 사용한 예제입니다. readiness probe는 Container가 시작되고 5초 이후 처음 수행하고 그 후 매 10초마다 수행하는 설정이고, liveness Probe는 Container가 시작되고 15초 이후 처음 수행하고 그 후 매 20초마다 수행하는 설정입니다. 두 Probe모두 8080 포트로 TCP connection을 체크하게됩니다.
아래 명령어로 Pod를 생성합니다.
4. readiness 프로브 정의
때때로 애플리케이션을 시작할 때에 어느정도 시간이 소요될 수 있습니다. 어떤 애플리케이션은 초기 시작시 데이터의 로딩시간이 필요할 수도 있고, 외부의 어떤 서비스와 연동되기 위한 시간이 필요할 수도 있습니다. 이런 경우에 정상적으로 서비스가 레디가 되는 것을 체크하는데 사용되어 질 수 있는 것이 readiness probe입니다.
Readiness probe의 설정은 liveness probe를 설정하는 방법과 동일합니다. 다만 readinessProbe 필드대신livenessProbe 필드로 설정하면 됩니다.
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
5. 프로브 설정
Configure Probes
Probes 는 보다 정확한 health체크를 위해 많은 설정필드를 가지고 있습니다.
initialDelaySeconds: Pod가 생성되고 Conainer가 시작된 이후 최초 probe가 수행되기전에 Delay를 주는 시간periodSeconds: probe의 수행주기를 설정. Default 10 seconds. Minimum value 1.timeoutSeconds: probe 수행 응답을 기다리는 timeout 시간을 설정. Default 1 second. Minimum value 1.successThreshold: probe가 최소 몇번을 성공해야 성공으로 마킹할 것인지를 설정하는 필드. Default 1. Minimum value 1.failureThreshold: probe가 최소 몇번을 실패해야 실패로 마킹할 것인지를 설정하는 Pod가 시작되고 Pobe가 실패하면 Kubernetes는 failureThreshold에 설정된 만큼 다시 probe를 시도할 것입니다. 다만 failureThreshold의 숫자만큼 실패하면 실패로 마킹되고 다시 probe를 시도하지 않고 포기하게 됩니다. Defaults 3. Minimum value 1.
HTTP probes 는 추가적으로 아래와 같은 필드를 더 설정할 수 있습니다.
host: 연결하려는 Host Name, default는 pod IP.scheme: HTTP or HTTPS. Defaults to HTTP.path: HTTP server에 접근하려는 경로.httpHeaders: Custom header 설정값.port: container에 접근하려는 Port.
2. Resource 할당
Kubernetes에서 Pod는 스케쥴링할때 Container가 실제로 수행 할 수 있는 충분한 컴퓨팅 리소스를 갖는 것은 매우 중요합니다. 만약 어떤 어플리케이션이 수행되기 위한 리소스보다 적은 리소스로 Node에 할당되게 되면, 메모리나 CPU문제로 어플리케이션이 중단될 수 있기 때문입니다. 또한 어플리케이션은 떄때로 필요한 것보다 더 많은 리소스가 필요 할 수 도 있습니다.
1. Resource requests and limits
Resource requests and limit은 Kubernetes가 CPU 및 메모리와 같은 리소스를 제어하는 매커니즘입니다.
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: wp
image: wordpress
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
컨테이너를 명세할 때 위와 같이 각각의 Container에서 필요한 CPU와 RAM을 CPU Milicore단위(1,000 Milicore = 1Core)로 Memory는 Mbyte 단위로 리소스의 requests과 limits(요청과 제한)이라는 측면에서 정의할 수 있습니다.
Container가 리소스를 Request하면 Kubernetes는 리소스를 제공할 수 있는 노드에서만 스케쥴링이 되고, Limit는 Container가 특정 리소스를 초과하지 않도록 제한합니다.
cpu
CPU 요청과 관련하여 고려해야 할 사항 중 한가지는 Node의 CPU core수보다 큰 값을 입력하면 Pod가 스케쥴링 되지 않는다는 것입니다. 예로써 Kubernetes 클러스터는 dual core VM으로 구성되어 있는데 Pod에는 4개의 core를 입력했다면 Pod가 스케쥴링 되지 않는다는 것입니다.
특별한 경우가 아니라면 CPU요청은 1이하로 하고 Replica에 의해 오토스케일링되는 것을 염두해서 Pod를 설계해야합니다. 이렇게 설정하는 것이 시스템을 보다 유연하고 신뢰성있게 구성할 수 있습니다.
Memory
Memory도 CPU와 마찬가지로 Node의 메모리보다 더 큰 요청을 셋팅하게되면 Pod는 스케쥴링되지 않습니다. 또한 메모리는 CPU와 달리 Kubernetes에서 메모리 사용량을 조절할 수 없으므로 Container가 메모리 제한을 초과하게 되면 애플리케이션(Container)가 종료되는데, Pod가 Deployment, StatefulSet, DaemonSet 또는 다른 유형의 컨트롤러에 의해 관리되는 경우, 기존 Pod는 종료되고 새로운 Pod가 시작됩니다.
Namespace settings
클러스터는 Namespace로 구성될 수 있는데, 만약 그 중 한 Namespace가 과도한 요청이 있을 경우 전체 클러스터에 영향을 미칠 수 있습니다. 따라서 이러한 경우를 제한하기 위해서는 Namespace 레벨에서 ResourceQuotas와 LimitRanges 를 설정하는 것이 중요합니다.
ResourceQuotas
Namespace를 생성한 후, ResourceQuota를 통해 Namespace의 CPU 및 메모리를 제한 할 수 있습니다.
LimitRange
ResourceQuotas는 Namespace 전체영역에 대한 리소스의 제한을 정의하는반면, LimitRange는 개별 컨테이너 단위의 리소스에 대한 제약입니다. 즉, 사용자들이 개별 컨테이너에 대한 리소스를 정의 할때 해당되는 범위를 제한하는 개념입니다. 이렇게 함으로써, 사용자들은 초소형 또는 초대형 컨테이너를 생성 할 수 없게 됩니다.